

皆さんこんにちはこんばんは、まずここブログを運営してます「よーす」です。
前回の記事でGoogle Cloud Vision APIを使ったOCR(光学的文字認識)紹介しましたが、今日は無料で使えるものOCRエンジン「Tesseract」を紹介していきます!
開発環境
- Windows 10
- 64ビット
- C#/Visual Studio 2019
ちなみに前回の記事はこちら
Tesseract OCRをC#プロジェクトに入れよう
今回Visual Studio 2019を使うので、NuGetを使ってちゃちゃっとTesseract入れてしまいましょう!
手順
プロジェクトのプロパティ → NuGetパッケージの管理
NuGetの画面を開いたら以下の画像のように検索してください。
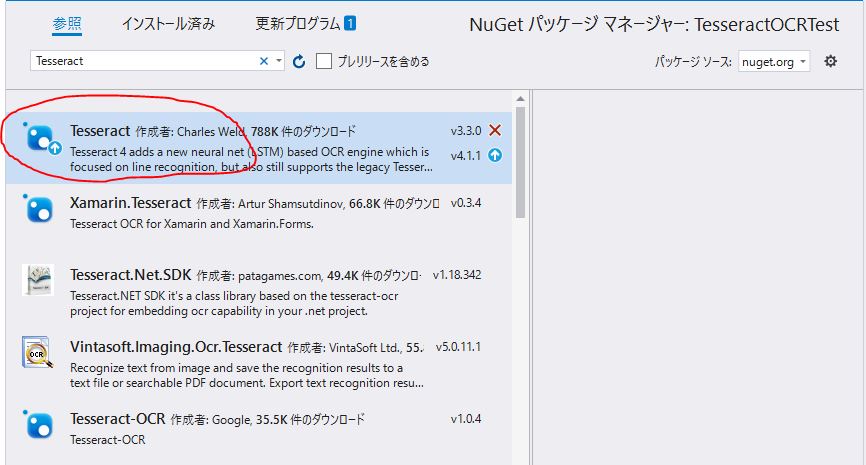
ここまで開けたら、Tesseractをクリックして、インストールをクリックします。
これで準備はオッケー!
Traineddataを準備しよう
このTrainedataというのは、OCRエンジンを使う上で必須になるのであらかじめ用意する必要があります。OCR処理をするときにこのTraineddataを参照して認識結果を出しているので、これがないとTesseract OCRが動きません。
ということで、以下のURLからTrainedataをダウンロードしましょう。
私は、日本語認識用で使うので「jpn.traineddata」をダウンロードしました。
任意の場所にファイルを置こう
Traineddataがダウンロードできたら、任意の場所に置きましょう。私は、EXEの直下に「tessdata」というフォルダを作ってその中に置きました。
Tesseract OCRを使ってOCR認識をしよう
これから実際のC#コードを紹介していきますが、Ver4.0は以前のバージョンとコードの書き方が少し変わっていて以下のコードでは昔のバージョンは動きませんので注意してください。
// Traineddataのパスを指定します。 string datapath = ""; // 日本語指定するための文字列も作成 string lang = "jpn"; // 画像パスを指定 string imgpath = ""; Tesseract.TesseractEngine tesseOCR = new Tesseract.TesseractEngine(datapath, lang); Tesseract.Pix image = Tesseract.Pix.LoadFromFile(path);// Ver3ではなかった Tesseract.Page page = tesseOCR.Process(image);//ver3ではBitmapを引数に渡せた // OCR結果を取得 string result = page.GetText();
以上です。
コメントにVer3との簡単な違いも記載してあるので、読んでみてください。
まとめ
とりあえずこれでOCR処理が実行できると思います。
認識率は、活字であれば結構使えるんじゃないかな~と思っています。
これから、Google Cloud Vison APIと一緒に認識結果を検証していくので楽しみにしていてください。
最後まで読んでいただきありがとうございます。
よかったらコメントを頂けると励みになります!